NVIDIA Riva
NVIDIA Riva é um framework de softwares para serviços de AI conversacional multimodal que oferece desempenho em tempo real em GPUs.
Riva é um framework de softwares totalmente acelerado para a criação de serviços de AI conversacional multimodal que seguem um pipeline de deep learning de ponta a ponta. Os desenvolvedores podem ajustar facilmente modelos de última geração de acordo com seus dados para entender melhor o seu contexto específico, otimizando a inferência e oferecendo serviços em tempo real de ponta a ponta que são executados em menos de 300ms, garantindo uma taxa de transferência 7 vezes maior com GPUs em comparação a CPUs.
O framework Riva conta com modelos pré-treinados de AI conversacional, ferramentas do Kit de Ferramentas de AI da NVIDIA e serviços otimizados de ponta a ponta para tarefas de fala, visão e compreensão de linguagem natural (NLU - Natural Language Understanding).
Com a união simultânea de visão, áudio e outras informações de sensores, é possível ter recursos como conversas com vários usuários e vários contextos em softwares como assistentes virtuais, de compromissos para vários usuários e de centrais de atendimento.
Os softwares baseados no Riva foram otimizados para maximizar o desempenho na plataforma NVIDIA EGX™ no cloud, no data center e no edge.
Desempenho em Tempo Real
Execute softwares de AI conversacional baseados em deep learning em menos de 300 ms, o limite de latência para o desempenho em tempo real.
Multimodal
Unifique fala e visão para oferecer interações precisas e naturais em assistentes virtuais, chatbots e outros softwares de AI conversacional.
Implementação Automatizada
Use um comando para implementar serviços de AI conversacional no cloud ou no edge.
“A Ping An atende a milhões de consultas de clientes todos os dias usando agentes de chat-bot. Como um dos primeiros parceiros do programa de acesso antecipado do Riva, fomos capazes de usar as ferramentas e construir soluções melhores com maior precisão e menor latência, fornecendo assim melhores serviços. Mais especificamente, com o NeMo, o modelo pré-treinado, e o pipeline ASR otimizado com Riva, o sistema obteve 5% de melhoria na precisão, de forma a atender nossos clientes com melhor experiência.”
— Dr. Jing Xiao, Cientista-Chefe da Ping An

“Em nossa avaliação do Riva para assistentes virtuais e análise de fala, vimos uma precisão notável ao ajustar os modelos de reconhecimento automatizado de fala no idioma russo usando o kit de ferramentas NeMo no Riva. O Riva pode fornecer desempenho de rendimento de até 10 vezes com otimizações TensorRT poderosas em modelos, por isso estamos ansiosos para usar Riva para obter o máximo desses avanços tecnológicos.”
— Nikita Semenov, Chefe de ML na MTS AI

“A InstaDeep oferece produtos e soluções de AI de tomada de decisão para empresas. Para este projeto, nosso objetivo é construir um assistente virtual na língua árabe, e NVIDIA Riva desempenhou um papel significativo na melhoria do desempenho da aplicação. Usando o kit de ferramentas NeMo no Riva, pudemos ajustar um modelo de fala para texto em árabe para obter uma taxa de erro de palavras tão baixa quanto 7,84% e reduzimos o tempo de treinamento do modelo de dias para horas usando as GPUs. Esperamos integrar esses modelos no pipeline de ponta a ponta do Riva para garantir latência em tempo real.”
— Karim Beguir, CEO e Cofundador da InstaDeep

“Na Intelligent Voice, fornecemos soluções de reconhecimento de voz de alto desempenho, mas nossos clientes estão sempre procurando mais. O Riva adota uma abordagem multimodal que funde elementos-chave do Reconhecimento Automático de Fala com correspondência de entidade e intenção para lidar com novos casos de uso onde rendimento e baixa latência são necessários. A API Riva é muito fácil de usar, integrar e personalizar os workflows de nossos clientes para desempenho otimizado.”
— Nigel Cannings, CTO da Intelligent Voice

“Na Northwestern Medicine, nosso objetivo é melhorar a satisfação do paciente e a produtividade da equipe com nosso conjunto de soluções de AI na área da saúde. A AI de conversação, desenvolvida pelo NVIDIA Clara Guardian e pelo Riva, melhorou a segurança do paciente e da equipe durante o COVID-19, reduzindo o contato físico direto e, ao mesmo tempo, oferecendo cuidados de alta qualidade. Os modelos Riva ASR e TTS tornam essa AI de conversação uma realidade. Os pacientes agora não precisam mais esperar que a equipe clínica esteja disponível: eles podem receber respostas imediatas de um assistente virtual equipado com AI.”
— Andrew Gostine, MD, MBA, CEO do Whiteboard Coordinator

“A baixa latência é crítica em call centers e, com as GPUs NVIDIA, nossos atendentes podem ouvir, entender e responder em menos de um segundo com os mais altos níveis de precisão. Com base nas primeiras avaliações de canais de compreensão de fala e linguagem no NVIDIA Riva, acreditamos que podemos melhorar a latência ainda mais, mantendo a precisão, oferecendo a melhor experiência possível para nossos clientes.”
— Alan Bekker, cofundador e CTO da Voca

“Por meio do programa de acesso antecipado do NVIDIA Riva, pudemos potencializar nossos produtos de AI de conversação com modelos de última geração usando NVIDIA NeMo, reduzindo significativamente o custo inicial. O reconhecimento de voz do Riva tem latência incrivelmente baixa e alta precisão. Ter a flexibilidade para implantar no local e oferecer uma variedade de opções de privacidade e segurança de dados para nossos clientes nos ajudou a posicionar nossos produtos habilitados para AI de conversação em novos setores da indústria.”
— Rajesh Jha, CEO da Siminsights.

“As aplicações de AI de conversação consomem muitos dados. Imagine os dados necessários para treinar modelos ou o armazenamento necessário para conter todas as informações para ter interações mais naturais e úteis. O Riva nos ajudou a aproveitar esses dados para atingir nosso objetivo de criar assistentes virtuais para lojas de varejo com mais rapidez. Os pipelines Riva usam modelos de deep learning de última geração e executam as aplicações de conversação em milissegundos.”
— AJ Mahajan, Diretor Sênior de Soluções na NetApp

Crie Modelos de Deep Learning de Última Geração

Use modelos de deep learning de última geração com mais de 100 mil horas de treinamento em sistemas NVIDIA DGX™ para tarefas de fala, compreensão de linguagem e visão. Os modelos e scripts pré-instalados usados no Riva estão disponíveis gratuitamente no NGC™.
Você pode ajustar esses modelos para seu domínio com seus dados usando NVIDIA NeMo e o Kit de Ferramentas Transfer Learning para implantá-los facilmente como serviços.
Desenvolva Novos Recursos Multimodais
Crie recursos multimodais, como transcrição de vários locutores, chatbots, reconhecimento de gestos e ativação com o olhar para seus softwares de AI conversacional.
O Riva vem com exemplos de vários recursos que você pode personalizar conforme seu caso de uso. Com o Riva, você pode usar pipelines visuais, de fala e de compreensão de linguagem, além de um gerenciador de caixas de diálogo compatível com vários usuários e contextos para criar outros recursos.

Serviços Otimizados para Tarefas Específicas
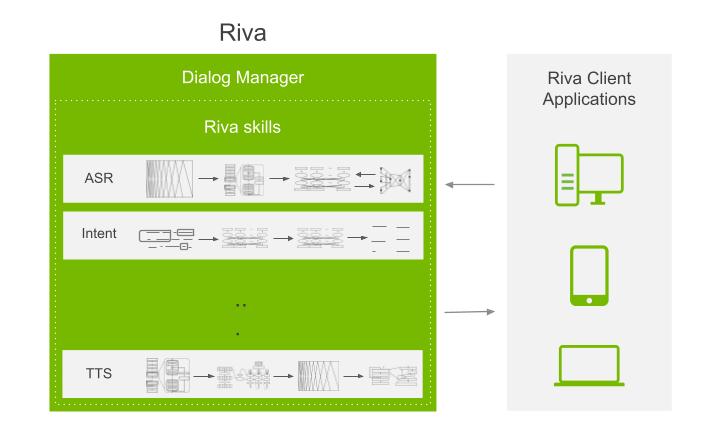
Acesse serviços de alto desempenho para tarefas como reconhecimento de fala, reconhecimento de intenção, conversão de texto em fala, estimativa de pose, detecção de olhar e detecção de pontos faciais com uma API simples.
É possível unir os pipelines de cada recurso para criar outros recursos. Todos os pipelines são ajustados para oferecer o maior desempenho possível e podem ser personalizados conforme seu caso de uso específico.
Crie e Implemente Serviços Facilmente
Automatize as etapas de modelos pré-treinados a serviços otimizados implementados no cloud, no data center e no edge. Além disso, o Riva aplica otimizações avançadas do NVIDIA® TensorRT™ a modelos, configura o Servidor de Inferência NVIDIA Triton™, e expõe os modelos como um serviço usando uma API padrão.
Na implementação, você pode usar um único comando para baixar, configurar e executar todo o software Riva ou serviços individuais por meio de pacotes Helm em clusters do Kubernetes. Os pacotes Helm podem ser personalizados conforme seu caso de uso e sua configuração.

Principais Adeptos nos Mercados Verticais
Recursos
Comece a Usar o NVIDIA
Riva
Compreenda os principais recursos do Riva que o ajudam a construir serviços de IA de conversação multimodais.
Modelos de Ajuste Fino com Kit de Ferramentas de Transfer Learning
Aprenda a ajustar modelos de última geração em seus dados para entender o termo específico do domínio.
Entenda os Recursos do
Riva
Descubra a tecnologia subjacente que pode criar assistentes virtuais interativos e automatizar call centers.
Crie Aplicações de AI de Conversação
Desenvolva sua primeira aplicação de AI de conversação que minimiza a latência e maximiza a taxa de transferência em GPUs.
Inscreva-se para receber notícias e atualizações do NVIDIA Riva Beta.